State of AI 2019 Report herunterladen
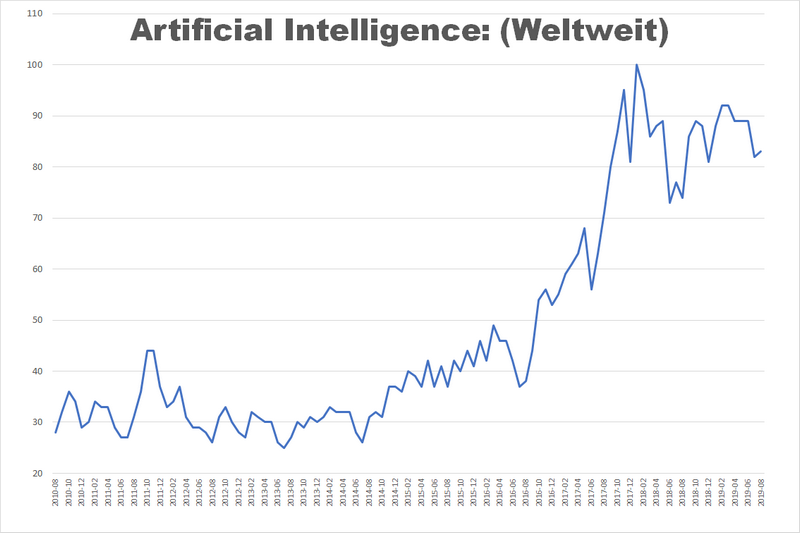
Eine Suche in Google Trends zeigt es deutlich: Künstliche Intelligenz (KI) bzw. Artificial Intelligence (AI) ist weltweit ein Hype. Der Suchbegriff wird etwa doppelt so häufig abgefragt wie am Anfang des Jahrzehnts. Dabei handelt es sich nicht um einen kurzlebigen Trend. Obwohl es ganz offensichtlich gewisse Konjunkturen gibt, ist das Interesse am Suchbegriff seit einigen Jahren kontinuierlich hoch. Und wer in das Suchfeld von Google den Begriff „Artificial Intelligence“ eingibt, erhält die ersten zehn von ungefähr 436 Millionen Webseiten zu diesem Stichwort präsentiert.
Es ist nur sehr schwer möglich, hier noch einen einigermaßen fundierten Überblick zu behalten. Einen ebenso wichtigen wie interessanten Ausschnitt aus der KI zeigt der Bericht State of AI 2019. Die beiden Autoren Nathan Benaich und Ian Hogarth sind langjährige Beobachter der KI-Szene als Investoren und Wissenschaftler. Sie präsentieren nach eigener Auskunft auf 136 Seiten „einen Schnappschuss der exponentiellen Entwicklung der KI mit einem Schwerpunkt auf Entwicklungen in den letzten zwölf Monaten“. Der Bericht widmet sich fünf wichtigen Schlüsselbereichen innerhalb der künstlichen Intelligenz und präsentiert sie in den folgenden Abschnitten:
- Research: Forschungsergebnisse und technologische Durchbrüche.
- Talent: Berufsbilder und Personalgewinnung in der KI.
- Industry: KI-Unternehmen und ihre Finanzierung.
- China: Neue KI-Trends in China.
- Politics: Die Behandlung der KI im Rahmen von Politik und Gesellschaft.
Da der Bericht nur schwer zusammenzufassen ist, habe ich einige besonders interessante Themen ausgewählt und sie jeweils in einem Kurzartikel dargestellt. Wer einen lesen möchte: Einfach auf den grauen Balken mit dem Thema klicken.
[toggle title=“Reinforcement Learning“]
Reinforcement Learning
Diese Form von Deep Learning ist in den letzten Jahren intensiv erforscht worden. Das Prinzip: Software-Agenten lernen zielorientiertes Verhalten durch Versuch und Irrtum. Sie agieren dabei in einer Umgebung, die ihnen positive oder negative Belohnungen als Reaktion auf ihre Handlungen gibt. Für das Training von neuronalen Netzwerken sind die KI-Entwickler dazu übergegangen, Computerspiele wie beispielsweise Montezuma’s Revenge (Jump’n’Run), Quake III Arena (Egoshooter) oder Star Craft II (Echtzeit-Strategiespiel) einzusetzen.
Solche Umgebungen, aber auch speziell angefertigte Computersimulationen eignen sich hervorragend dazu, Verhalten zu variieren und anschließend erfolgreiches Verhalten zu wiederholen. Darüber hinaus sind die Belohnungen bereits in die Games integriert. In der realen Welt sind variantenreiche Lernumgebungen nicht so einfach umzusetzen, etwa für die Robotik.
So hat OpenAI eine Roboterhand in einer Simulation darin trainiert, physikalische Objekte zu manipulieren. Auch das zweibeinige Gehen wird gerne in Simulationen geprobt, denn es ist weniger einfach, als wir Menschen intuitiv glauben. Um nicht regelmäßig teuren Elektroschrott zu erzeugen, werden gehende Roboter deshalb ebenfalls in Simulationen trainiert. Dabei wird unter anderem Reinforced Learning genutzt.
Simulationen und Computerspiele eignen sich gut zum Trainieren von lernfähigen Systemen, da sie kostengünstig und weithin verfügbar sind. Im Grunde kann jeder Entwickler damit arbeiten, auch ohne Risikokapital im Hintergrund. Darüber hinaus können die Spielumgebungen unterschiedlich komplex gestaltet werden. Das ist einer der Gründe, warum Open World Games wie Grand Theft Auto gerne beim grundlegenden Training von Deep-Learning-Modellen für das autonome Fahren genutzt werden.
Sind Games und Simulationen also die optimale Umgebung für das KI-Training? Sicher nicht, wie auch die Autoren des Berichts nahelegen. Denn jede simulierte Welt ist deutlich weniger komplex als die wirkliche Welt. Im Normalfall wird das Ergebnis niemals ein austrainiertes KI-Modell sein, das direkt und ohne Probleme in der Wirklichkeit eingesetzt werden kann. Die Erfahrungen mit den bisherigen KI-Anwendungen für fahrerlose Autos zeigen, dass hier auch ein altbekanntes Prinzip für die Optimierung von Prozessen gilt: Die letzten Prozent der zu trainierende Fähigkeiten machen mindestens so viel Aufwand wie der Rest.
[/toggle]
[toggle title=“Natural Language Processing“]
Natural Language Processing
Alexa, Siri & Co. haben in den letzten Jahren gezeigt, dass Natural Language Processing (NLP) recht weit fortgeschritten ist und es zahlreiche alltagstauglich Anwendungen gibt — in bestimmten Bereichen. Schwierig sind echte Dialoge mit Rückbezügen auf vorher Gesagtes. Außerdem kommt das menschliche Gehirn immer noch besser mit dem uneigentlichen Sprechen wie Ironie oder Hyperbeln zurecht. Wer mit Alexa redet, muss eindeutig und in Anweisungsform sprechen, typisch menschliche Unschärfen in der Aussage führen meist nicht zum Ergebnis.
Die Erkenntnis zahlreicher Projekte: Vortrainierte Sprachmodelle verbessern die Ergebnisse von NLP deutlich. Im Bereich Computer Vision sind damit große Erfolge erzielt worden. So werden beispielsweise viele neuronale Netze für die Bilderkennung mit ImageNet vortrainiert und erst dann mit weiterem Training an den speziellen Anwendungsfall angepasst. Dieses Dataset besteht aus momentan knapp 14,2 Millionen Bildern, die nach fast 22.000 semantischen Kategorien indiziert sind. Diese wiederum sind nach den Prinzipien der lexikalisch-semantischen Datenbank WordNet organisiert.
Eine vergleichbare Vorgehensweise ist auch bei NLP sinnvoll, denn es ist aufwendig, valide Trainingsdaten für Teilaufgaben zu entwickeln — beispielsweise das Bestellen einer Pizza, wie es Google Duplex beherrschen soll. Google hat vor einiger Zeit eine Technik für das Vortrainieren von NLP-Modellen als Open Source freigegeben. Das Ergebnis heißt BERT (Bidirectional Encoder Representations from Transformers) und basiert auf demselben Neuronetz wie Google Translator. BERT kann vergleichsweise einfach durch ein Zusatztraining an die jeweilige Aufgabe angepasst werden.
Zudem kann BERT auch durch weitere Lernverfahren ergänzt werden, beispielsweise durch Multi-Task Learning (MTL). Eine Demo dieser Möglichkeiten bietet Microsoft Research mit seinem Multi-Task Deep Neural Network (MT-DNN). Dabei werden verschiedene, aber verknüpfte Aufgaben gleichzeitig gelernt, wodurch der Lernfortschritt größer wird. Pate war hier eine Eigenheit des menschlichen Lernens: Wer bereits gut auf Inlinern skaten kann, lernt das Schlittschuhfahren deutlich schneller als jemand ohne Inliner-Erfahrung.
Der Einsatz vortrainierter Modelle hat in der Computer Vision manchen Durchbruch gebracht, Benaich und Hogarth hoffen, dass dies ebenso für das Verständnis menschlicher Sprache durch neuronale Netze gilt.
[/toggle]
[toggle title=“Rückkehr der symbolischen KI“]
Rückkehr der symbolischen KI
Das Verstehen natürlicher Sprache ist ein wesentliches Element von Sprachassistenten. Doch zahlreiche Praktiker sind mit reinen KI-Modellen über ein Problem gestolpert: Domänenwissen lässt sich einem Neuronetz nicht ohne weiteres antrainieren, denn das Training ist aufwendig und die Gewinnung von validen Datasets teuer.
Hier kommt dann ein Ansatz ins Spiel, der Mitte der achtziger Jahre als der Königsweg zur künstlichen Intelligenz galt: Symbolische KI, die unter anderem mit Verzeichnissen von Regeln und Alltagswissen arbeitet, um das Schlussfolgern aus Common-Sense-Sachverhalten zu ermöglichen. Die bekannteste Datenbank dieser Art ist Cyc und wird seit 1984 schrittweise aufgebaut.
Dieser Ansatz galt über lange Jahre hinweg als gescheitert, da selbst eine noch so große Datenbank nicht das gesamte Weltwissen enthalten kann. Doch als Partnerverfahren ist Domänenwissen inzwischen wieder wertvoll für KI. Denn eine Datenbank wie Cyc kann ein Deep-Learning-System durch Wissensprimitive ergänzen, sodass das Training sich ausschließlich High-Level-Sachverhalten widmen kann.
[/toggle]
[toggle title=“Autonome Fahrzeuge“]
Autonome Fahrzeuge
Roboterautos und andere autonome Fahrzeuge gehören zu den wichtigsten Zukunftsvisionen bei KI. Einer der Vorreiter ist Waymo, dessen autonome Fahrzeugflotte auf den US-Straßen mehr als 16 Millionen Kilometer bewältigt und dabei wichtige Fahrdaten gesammelt hat. Die Daten von weiteren 11 Milliarden Kilometern in Computersimulationen kommen hinzu. Allein im letzten Jahr haben die 110 Waymo-Wagen in Kalifornien mehr als 1,5 Millionen Kilometer bewältigt.
Hinzu kommt der Datensatz von Tesla, der durch Auswertung aller von jedem einzelnen Tesla-Modell gefahrenen Kilometer entsteht. Die genaue Fahrleistung ist unbekannt, wird aber auf mehr als zwanzig Milliarden Kilometer geschätzt. Was die Menge der Daten angeht, dürfte Tesla einen uneinholbaren Vorsprung vor der Konkurrenz haben. Hinzu kommt: Das Unternehmen entwickelt seinen eigenen KI-Chip. Die Analysten des institutionellen Investors ArkInvest schätzen, dass Teslas Konkurrenten beim autonomen Fahren drei Jahre hinterher fahren.
Es ist allerdings sehr schwer, den tatsächlichen Erfolg der einzelnen Anbieter von Robotertaxis einzuschätzen. Einen kleinen Hinweis geben die von der kalifornischen Straßenbehörde veröffentlichten Disengagement-Reports. Danach schaffen Fahrzeuge von Waymo eine Jahresfahrleistung von fast 50.000 Kilometern mit lediglich einem oder zwei Aussetzern („Disengagements“), bei denen der menschliche Testfahrer übernehmen musste. Zum Vergleich: Auch Mercedes testet in Kalifornien. Doch 2018 waren es nur vier Fahrzeuge mit wenigen hundert Kilometern Fahrleistung, aber etlichen hundert Aussetzern.
Von Tesla gibt es übrigens keine Angaben dazu. Das Unternehmen sammelt zurzeit in erster Linie Fahrdaten, vermutlich um seine Modelle in Simulationen zu trainieren. Trotz des Vorsprung: Selbst der Datensatz von Tesla ist im Vergleich zu den menschlichen Fahrleistungen winzig. So wird die Gesamtfahrleistung nur der kalifornischen Autofahrer für das Jahr 2017 auf knapp 570 Milliarden Kilometer geschätzt. Dem stehen etwa 485.000 Autounfälle gegenüber, was einem Disengagement auf jeweils 1,2 Millionen Kilometer entspricht. Kurz: Das Robotertaxi scheint noch einige Zeit entfernt zu sein.
[/toggle]
[toggle title=“Robotic Process Automation“]
Robotic Process Automation
Robotic Process Automation (RPA) hat nichts mit Robotik zu tun, sondern ist ein Verfahren der Prozessautomatisierung und nachfolgend der Kostensenkung in Unternehmen. Das klingt im ersten Moment langweilig, ist aber ein spannendes Anwendungsgebiet in der KI. Denn es wird in der Praxis bereits eingesetzt und ist zu einem Markt mit hohen Erwartungen geworden: Anbieter wie UiPath sind mit 800 Millionen Dollar und Automation Anywhere mit 550 Millionen Dollar Risikokapital ausgestattet.
Für Unternehmen, die mit der Digitalisierung ihrer Prozesse kämpfen, ist RPA eine interessante Sache. Vereinfacht ausgedrückt ersetzen RPA-Anwendungen die menschlichen Endanwender in der vorhandenen Software-Infrastruktur. Dadurch ist es möglich, Prozesse zu automatisieren, die mehrere Anwendungen übergreifen, vor allem, wenn es keine definierten Software-Schnittstellen dafür gibt. RPA-Anwendungen sind in aller Regel lernfähig, sodass sie vergleichsweise leicht auch an exotische Altysteme anzupassen sind.
[/toggle]
[toggle title=“Demand Forecasting“]
Demand Forecasting
Ein brandneues Thema ist Demand Forecasting nicht, unter dem Stichwort Bedarfsermittlung wird es bereits seit längerer Zeit mit statistischen Methoden oder Fuzzy Logic umgesetzt. Es geht dabei um die Prognose der Anforderung bestimmter Ressourcen anhand von historischen Daten. Dabei wird zunehmend Machine Learning eingesetzt, um auch externe Daten (Wetter, Verkehr, Kundenströme usw.) zu berücksichtigen.
Es gibt einige Branchen und Anwendungsgebiete, in denen Demand Forecasting erfolgreich eingesetzt wird: So ermitteln Energieversorger beispielsweise den Strombedarf anhand von Wetterinformationen, Betriebsdaten und gemessenen Leistungsanforderungen. Zur Vorbereitung auf Starkregenfälle mit anschließenden Überflutung-Szenarien erschließt Machine Learning auf der Basis von historischen hydrologischen Daten neue Wege der Vorhersage von Fluten.
In Handel, Logistik, Gastronomie, Hotellerie und Touristik ordnet Machine Learning Ressourcen deutlich flexibler zu als herkömmliche Methoden. Ein Beispiel: Die Nachfrage nach bestimmten Produkten oder Services ist unter anderem vom Wetter, der aktuellen Verkehrslage in der Region, jahreszeitlichen Trends, aktuellen Moden bei Farbe oder Form und vielen anderem abhängig. Mit Machine Learning werden solche Faktoren berücksichtigt.
Große Supermarktketten müssen täglich Entscheidungen über Aufnahme, Streichung oder Nachbestellung von Millionen Einzelposten treffen. Ohne KI-Verfahren wird dies in der Zukunft schwer möglich sein, da einfache „Daumenregeln“ zu Schnelldrehern und Produktplatzierungen die immer dynamischer werdende Nachfrage kaum noch abbilden.
[/toggle]